안녕하세요 미이밍입니다.

전에 하려고 했던 프로젝트인데 이제 하게 되었네요
왜냐면 저도 이제 석사거든요!
틈틈히 시간날때 SPSS를 활용한 통계분석에 대하여 포스팅 해보려고 해요
가장 기초인 변수 부터 회귀분석, 매개효과, 조절효과, 조절된매개효과 등 까지 달릴거에요
연구방법론은 아마 필요없으실거라 생각해서 패스 할게요
나중에 SPSS완결 나면 연구방법론은 생각해볼게요 ㅎ.ㅎ
그럼 시작합니다

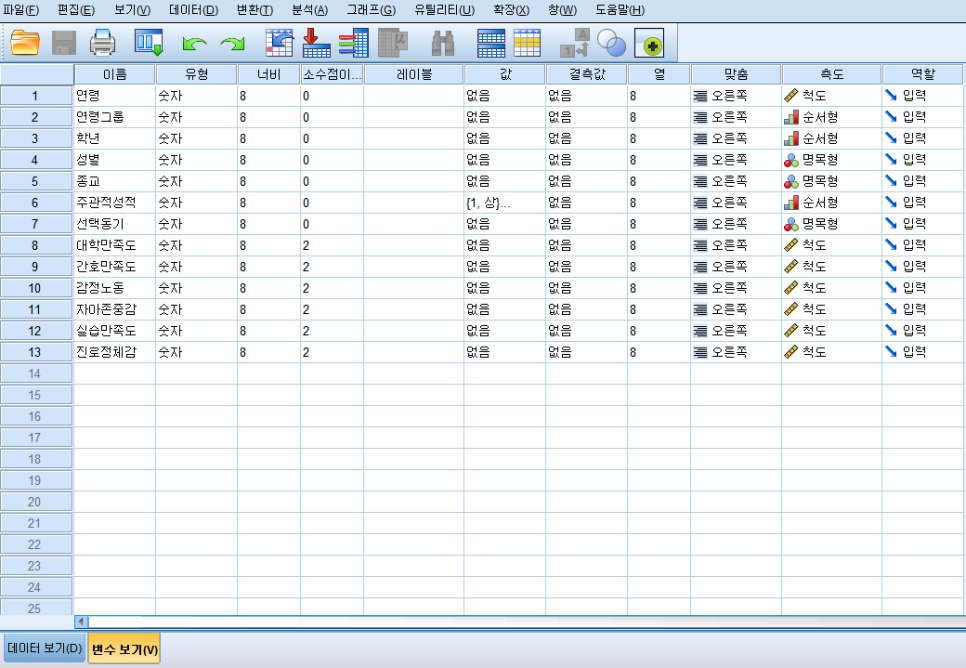
변수 보기는 데이터 코딩 전 변수에 대해 세팅하는 화면입니다.
1.이름

1)기본
변수명은 간단하고 쉬운 단어로 설정하며, 중복되어서는 안됩니다.
변수 보기에서 변수명을 지정하고, Backspace 키를 누르거나, del키를 눌러도 삭제되지 않으며
변수 자체를 삭제하기 위해선 변수명 왼쪽에 있는 숫자를 우클릭 후 지우기를 눌러주면 됩니다.
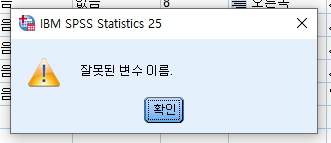
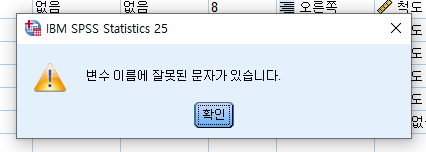
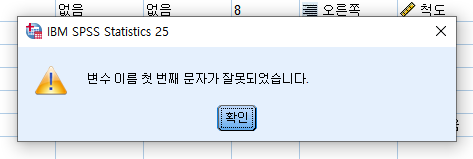
2)사용할 수 없는 문자
사용할 수 없는 문자가 있는데 !,#,$,% 등의 특수문자와 띄어쓰기를 사용할 수 없습니다.
사용 시 위와 같은 문구가 나오며, 특수문자 중 @는 사용이 가능합니다.
또한 숫자, 마침표, 밑줄은 사용이 가능하지만 변수 이름의 첫번째 문자로는 사용할 수 없습니다.
2.유형
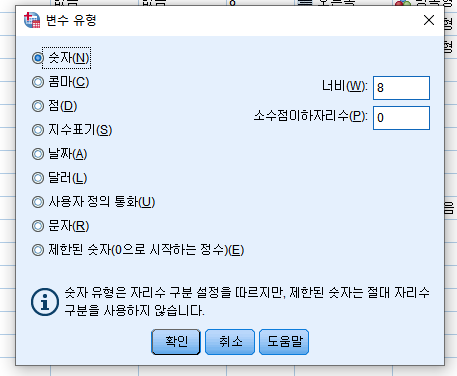
1) 기본
변수 유형은 각 변수에 대한 데이터 유형을 지정하는 것으로 기본적으로 모든 새 변수는 숫자로 가정합니다.
일반적으로 SPSS를 사용할 경우 숫자 또는 문자 유형위주로 사용하게 될 것입니다.
2) 숫자
변수값이 숫자인 변수입니다. 변수는 표준 숫자 형식으로 표시됩니다. 데이터 편집기에서는 표준 형식 또는 지수 표기법의 숫자값이 허용됩니다.
3) 문자
해당 값이 숫자가 아니어서 계산에 사용되지 않는 변수입니다.
값으로는 정의된 길이까지 어떤 문자든지 사용할 수 있습니다.
대문자와 소문자는 구별되며, 이 유형을 문자숫자형 변수라고도 합니다.
3.너비
열 너비에 대한 문자 수를 지정할 수 있으며, 열 너비를 바꾸어도 정의한 변수 자릿수는 바뀌지 않습니다.
또한 변수의 너비는 소수점 이하 자릿수보다 작을 수 없습니다.
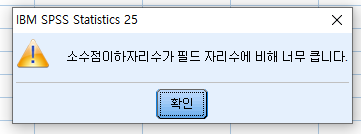
4.소수점 이하 자리
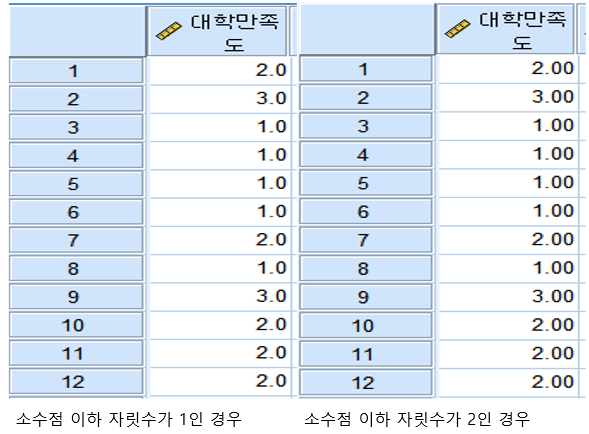
데이터가 소수점 이하 몇 번째 자리까지 표시될 지를 나타내는 것입니다.
5. 레이블
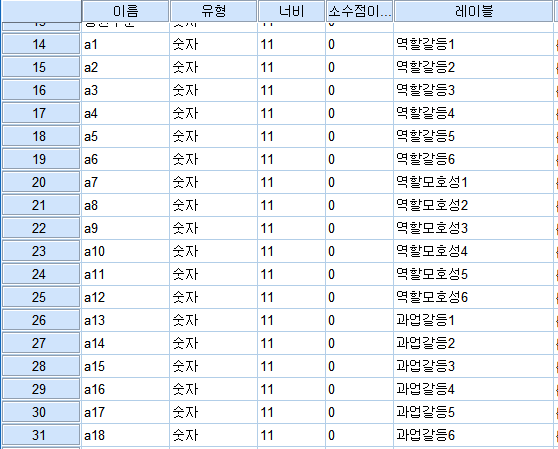
변수명을 간단히 적은 경우 작성자가 헷갈릴 수 있으며, 다른 연구자가 봤을때 알 수 없을수도 있습니다.
그럴 경우 변수에 대해 추가 설명을 적는 곳입니다.
변수 설명 레이블은 최대256자(더블바이트 언어의 경우128자) 까지 지정할수 있으며, 변수 이름으로 사용 할 수 없는 공백 및
예약된 문자(ALL, AND, BY, EQ, GE, GT, LE ,LT ,NE, NOT, OR, TO, WITH)가 포함될 수 있습니다.

6. 값
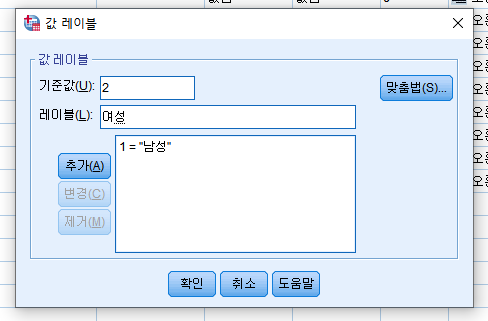
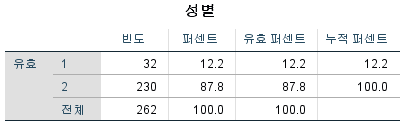
값 설정 전
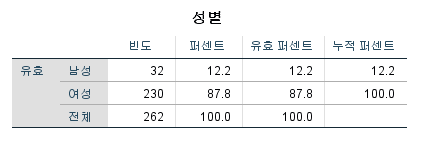
값 설정 후
명목척도 또는 순위척도와 같은 범주형 자료의 값을 설정합니다.
1) 설문지 변수 입력
설문지 문항 중 성별에 대해 묻는 항목이 있습니다.
1번이 남성, 2번이 여성일 경우, 값 레이블에서 기준값에 1, 레이블에 남성이라고 입력 후 추가 버튼을 누르면 값이 설정됩니다.
여성도 위와 마찬가지로 기준값에 2, 레이블에 여성이라고 입력하고 추가 버튼을 누르면 값이 설정됩니다.
그러면 출력값에서 단순히 1과 2로 표시되는 것이 아니라, 1은 남성, 2는 여성으로 변환되어서 출력됩니다.
2) 그룹화
분석을 하기 위해 코딩한 자료를 조작할 수 있습니다.
이 경우 연속형 변수를 범주형 변수로 조작하는 경우가 있는데, 이 경우에도 조작한 변수의 값 설정을 할 수 있습니다.
2. 결측값

1) 입력
결측값을 설정하기 전에 우선 데이터를 조작해야 합니다.
설문지의 데이터를 입력하다 보면 잘못 기입된 수치들이 있습니다.
대부분 이런 결측값들은 9,99,999등을 많이 사용하고 연구자가 임의로 설정해도됩니다.
예를들어 , 잘못 응답한 경우를 9, 무응답인 경우 99로 입력합니다.
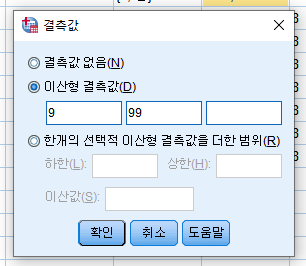
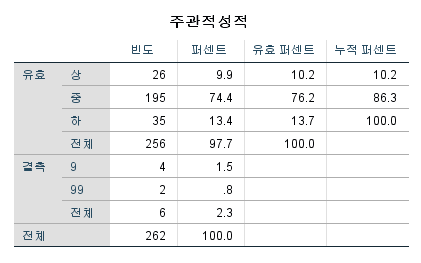
2) 이산형 결측값
값을 입력 후 결측값에서 설정해줘야 합니다.
위의 경우에는 잘못 응답한 모든 경우를 9로 입력하고 무응답인 경우 99로 입력하였습니다.
결측값은 위처럼 설정해주면 위와 같이 출력됩니다.

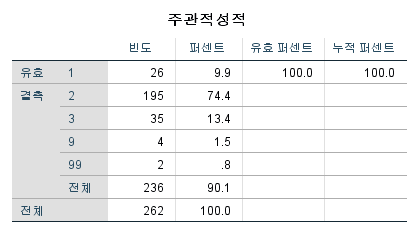
3) 한 개의 선택적 이산형 결측값을 더한 범위
다음과 같은 경우가 있을 수 있습니다.
예를 들어 1을 제외한 2번부터 9번까지는 결측값이고, 이외에는 99번이 결측값인 경우 입니다.
이럴 경우에는 위의 이산형 결측값에서 모든 값을 입력할 수 없습니다.
그렇기 때문에 최소값을 하한에 적고 최댓값을 상한에 적습니다.
그리고 범위 안에 속하지 않는 결측값을 이산값에 기입하면 됩니다.
만약 범위 안에 모든 결측값이 포함된다면 이산값을 따로 적지 않아도 됩니다.
3. 열
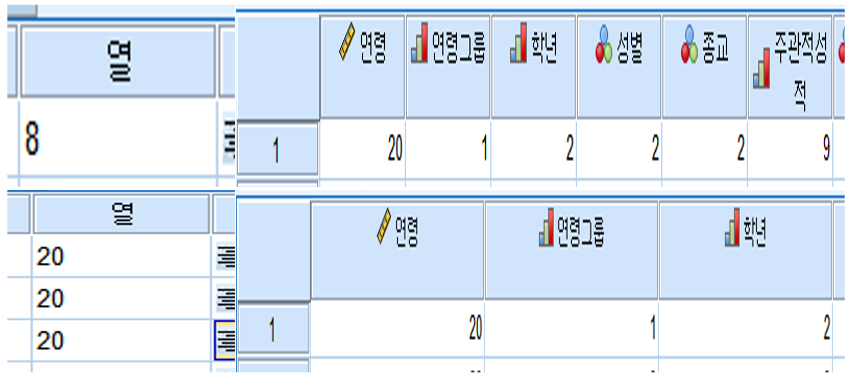
데이터의 칸 너비를 조정합니다.
열의 값이 커질수록 데이터가 입력된 칸의 너비가 넓어집니다.
4. 맞춤
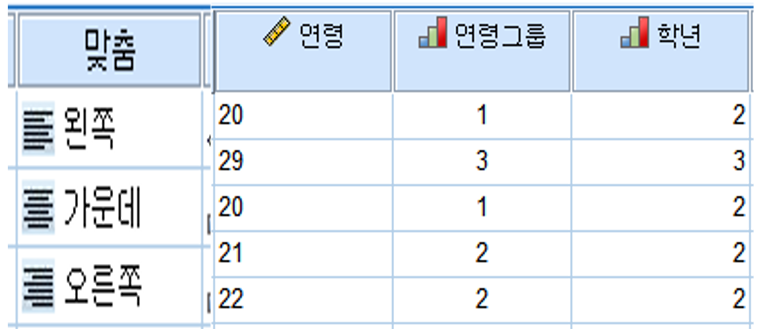
데이터의 위치를 설정합니다.
5. 측도

1)종류
척도 : 등간척도, 비척도
순서형 : 순위척도(서열척도)
명목형 : 명목척도
2)구분
|
|
구분
|
척도
|
비교방법
|
통계
|
|
분류
|
비계량적
|
명목척도
|
확인 ⸳ 분류
|
최빈값
|
|
순위척도
|
순위, 등급
|
최빈값, 중앙값
|
||
|
계량적
|
등간척도
|
간격
|
최빈값, 중앙값, 살술평균
|
|
|
비척도
|
절대크기
|
최빈값, 중앙값, 기하평균, 변동계수 등
|
6. 역할

분석에 사용되는 변수를 미리 선택하는데 사용할 수 있도록 하는 기능이며 T-Test나 회귀분석 등의 분석 시 따로 설정을 하지 않아도 됩니다.
1)입력 : 변수가 입력(예 : 에측변수, 독립변수)으로 사용됩니다.
2)목표 : 변수가 결과 또는 대상(예 : 종속변수)으로 사용됩니다.
3)모두 : 변수가 입력 및 결과 둘 다로 사용됩니다.
4)없음 : 변수에 역할이 할당되지 않습니다.
5)파티션 : 변수가 훈련, 검정, 검증용으로 별도의 표본에 데이터를 분할하는데 사용됩니다.
6)분할 : 라운드 트립 호환성용으로 포함되며, 이 역할이 있는 변수는 IMS SPSS Statistics에서 분할 파일 변수로 사용되지 않습니다.
'통계학 한 발자국' 카테고리의 다른 글
| [SPSS통계분석 기초] 코딩변경 (0) | 2024.04.05 |
|---|---|
| [SPSS 통계분석 기초] 변수계산 (0) | 2024.04.05 |
| [SPSS통계분석 기초] 케이스 선택 (1) | 2024.04.04 |
| [SPSS통계분석 기초] 파일 합치기 및 파일 분할 (0) | 2024.04.04 |
| [SPSS 통계분석 기초] 텍스트 파일 및 엑셀 파일 불러오기 (0) | 2024.04.03 |




댓글