1. 신뢰도 분석
1) 정의
신뢰도는 측정하고자 하는 것을 얼마나 일관성 있게 측정하는 지를 나타내는 것으로 신뢰도 분석은 항목들의 일관성을 파악하는 분석입니다.

2) 신뢰도 분석 중 통계량
① 항목 : 여러 케이스의 항목에 대한 기술통계량을 생성합니다.
② 척도 : 척도에 대한 기술통계량을 생성합니다.
③ 항목제거시 척도 : 다른 항목으로 구성된 척도에 각 항목을 비교하여 요약 통계를 보여 줍니다. 통계에는 척도에서 항목이 삭제된 경우의 척도 평균 및 분산, 삭제된 항목과 다른 항목으로 구성된 척도 간 상관 및 항목이 삭제된 경우의 Cronbach 알파가 포함됩니다.
④ 평균 : 항목 평균에 대한 요약 통계입니다. 최소, 최대 및 평균 항목 평균, 항목 평균의 범위 및 분산, 최소 항목 평균에 대한 최대 항목 평균의 비율이 표시됩니다.
⑤ 분산 : 항목 분산에 대한 요약 통계입니다. 최소, 최대 및 평균 항목 분산, 항목 분산의 범위 및 분산, 최소 항목 분산에 대한 최대 항목 분산의 비율이 표시됩니다.
⑥ 공분산 : 항목 간 공분산에 대한 요약 통계입니다. 최소, 최대, 평균 항목 간 공분산, 항목 간 공분산의 범위 및 분산, 최소 항목 간 공분산에 대한 최대 항목 간 공분산의 비율이 표시됩니다.
⑦ 상관계수 : 항목 간 상관관계에 대한 요약 통계입니다. 최소, 최대, 평균 항목 간 상관관계, 항목 간 상관관계의 범위 및 분산, 최소 항목 간 상관관계에 대한 최대 항목 간 상관의 비율 등이 표시됩니다.
⑧ F-검정 : 반복 측도 분산 분석표를 출력합니다.
⑨ Friedman 카이제곱 : Friedman 카이제곱과 Kendall 일치계수를 표시합니다. 이 옵션은 순위 형식의 데이터에 적합합니다. 카이제곱 검정은 분산 분석표의 일반적인 F 검정을 대체합니다.
⑩ Cochran 카이제곱 : Cochran의 Q를 표시합니다. 이 옵션은 이분형 데이터에 적합합니다. Q 통계는 분산 분석표에서 일반적인 F 통계를 대체합니다.
⑪ Hotelling의 T 제곱 : 척도의 모든 항목의 평균은 0이라는 귀무가설에 대해 다변량 검정을 생성합니다.
⑫ Tukey의 가법성 검정 : 항목 간에 다변량 반복을 하지 않는 가정에 대한 검정을 생성합니다.
⑬ 급내 상관계수 : 케이스 내에서 측도의 일치 또는 값의 일치를 생성합니다.
⑭ 모형 : 급내 상관계수를 계산하는 모형을 선택합니다. 사용할 수 있는 모형은 이차원 혼합, 이차원 변량, 일차원 변량입니다. 사람 효과가 랜덤 효과이고 항목 효과가 고정 효과인 경우 이차원 혼합 모형을 선택하고, 사람 효과와 항목 효과가 모두 랜덤 효과인 경우 이차원 변량 모형을 선택하거나 사람 효과가 랜덤 효과인 경우 일차원 변량을 선택합니다.
⑮ 유형 : 지수의 유형을 선택합니다. 사용할 수 있는 유형은 일치와 절대 동의입니다.
⑯ 신뢰구간 : 신뢰구간의 수준을 지정합니다. 기본값은 95%입니다.
⑰ 검정값 : 가설 검정에 사용하는 가설의 계수값을 지정합니다. 이 값은 관측값의 비교 대상이 되는 값입니다. 기본값은 0입니다.
3) 신뢰도 분석
① 메뉴를 선택합니다.

② '항목' 입력칸에 분석하고자 하는 변수들을 지정하고, '통계량'을 클릭합니다.


③ 다음에 대한 기술통계에서 '항목제거시 척도'를 설정하고, '계속'을 클릭합니다.


④ '확인'을 클릭하면, 다음과 같이 출력됩니다.
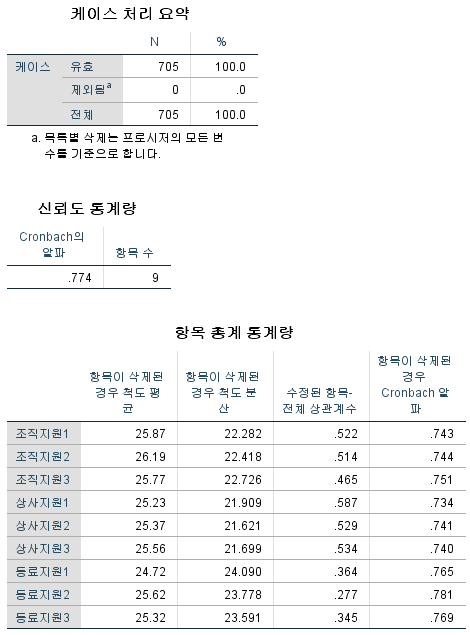
⑤ 알파 계수는 0. 6 이상이면 수용할 수 있습니다. 0.6보다 수치가 높을수록 우수하다고 판단합니다.

⑥ '항목이 삭제된'이라는 단어를 볼 수 있는데, 해당 변수가 삭제되었을 때의 값을 말합니다. 조직지원1을 보시면 '항목이 삭제된 경우 Cronbach 알파' 값이 .743인데 즉, 조직지원1이라는 변수가 삭제되었을 때 Cronbach 알파값이 .743이 될 것이라는 뜻입니다.

'통계학 한 발자국' 카테고리의 다른 글
| [SPSS통계분석 기초] 교차분석(Chi-square test) 카이분석, 카이제곱검정 (0) | 2024.04.08 |
|---|---|
| [SPSS통계분석 기초] 가중치 케이스 (0) | 2024.04.07 |
| [SPSS통계분석 기초] 타당도분석(요인분석) (0) | 2024.04.07 |
| [SPSS통계분석 기초] 기술통계 (0) | 2024.04.06 |
| [SPSS통계분석 기초] 빈도분석 (0) | 2024.04.06 |




댓글